Estudo de caso Cyclistic
17/10/2022
1. Introdução
Este é um estudo de caso realizado como projeto final do curso de especialização em Análise de Dados do Google. O código fonte do projeto se encontra aqui.
A empresa ficcional Cyclistic trabalha com o serviço de bike-sharing (bicicletas compartilhadas), e está localizada em Chicago, Estados Unidos. A Cyclistic possui mais de 5.800 bicicletas rastreadas geograficamente e uma rede de mais de 690 estações. As bicicletas podem ser retiradas de uma estação e retornadas à outra no sistema, em qualquer momento.
O serviço de bike-sharing possui dois tipos de usuários: membros anuais e casuais. O diretor de marketing acredita que o futuro sucesso da empresa depende de maximizar o número de membros anuais, e para isso, pediu uma análise de como os tipos de membros diferem no uso do serviço, além de recomendações de como transformar membros casuais em membros anuais
2. Processo
Meu primeiro passo foi coletar os dados das viagens feitas durante o último ano. A Cyclistic providenciou tais dados, divididos por mês. A licensa para o uso deste dataset se encontra aqui.
Para cada mês, há entre 100.000 e 500.000 entradas, salvas em arquivos csv. Devido ao tamanho dos arquivos, eu usei a linguagem de programação R, uma ferramenta otimizada para manipular, analisar e visualisar grandes quantidades de dados, para realizar essa tarefa. A possibilidade de qualquer erro humano ou viés é praticamente nula, pois os dados foram coletados pelas próprias bicicletas. Em relação à regras de privacidade de dados, não há informações pessoais dos usuários.
As viagens com menos de 60 segundos de duração (prováveis falsos inícios ou usuários tentando re-travar a bicicleta por garantia) foram removidas. Os dados foram limpos e todos os 12 datasets foram unidos em um só, removendo elementos incompletos, resultados de testes e viagens com tempo de duração negativos, além de ordená-los por suas variáveis de data e tempo. A documentação e o código completo para esta fase da análise podem ser encontrados aqui.
O dataset limpo foi, por fim, salvo com o nome de “all_trips_cleaned”.
3. Análise
3.1 Estações mais populares
O mapa interativo demonstra que as estações próximas à costa e ao píer naval são as mais populares, sendo a estação Streeter Dr & Grand Ave a mais popular delas, com 64.998 viagens. Pode-se deduzir, a partir de tais observações, que a maioria dos usuários usa o serviço para lazer.
É possível observar, também, que as estações mais ao sul do mapa são as menos populares, mesmo cobrindo boa parte da área. Isso indica que apenas uma pequena parte dos membros utilizam o serviço em regiões mais residenciais, enquanto a grande maioria dos membros se concentram em regiões centrais e turísticas da cidade.
3.2 Época mais popular do ano
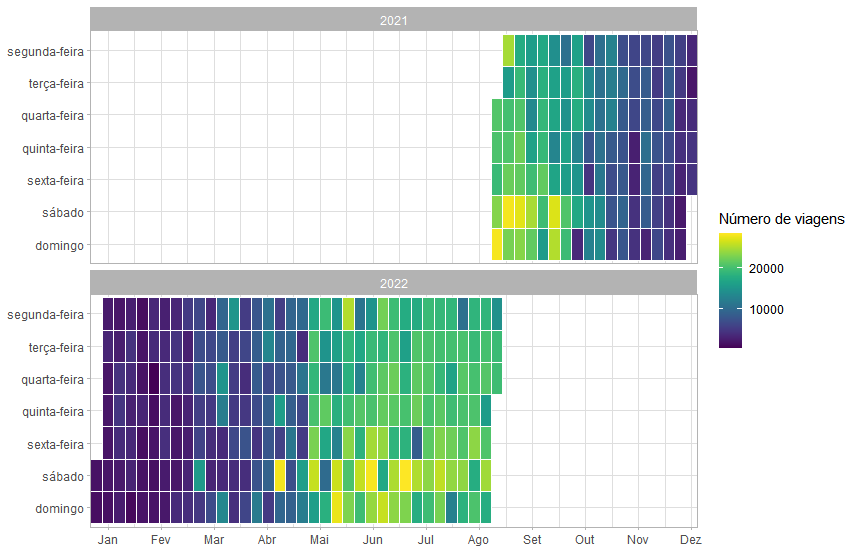
O mapa de calor acima apresenta o número de viagens feitas a cada dia da semana, ao longo de todo o período analisado, e mostra que os meses cuja estação do ano era o verão no hemisfério norte (onde se encontra a cidade de Chicago) foram os mais populares, especialmente seus finais de semana, ressaltando o ponto de que a maioria dos usuários usa o serviço para lazer.
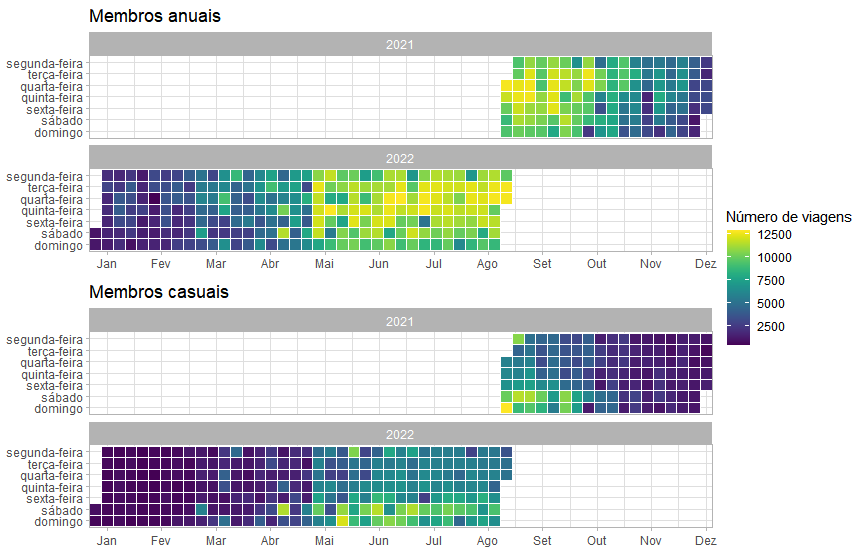
Separando o mapa de calor por membros anuais e casuais, é possível perceber o uso mais expressivo do serviço por parte dos primeiros, particularmente em dias úteis da semana, enquanto casuais concentram seu uso em finais de semana dos meses de verão.
Tais diferenças observadas indicam que membros anuais tendem a utilizar o serviço mais para trabalho do que para lazer, enquanto que para casuais, essa tendência se inverte.
3.3 Hora mais popular do dia
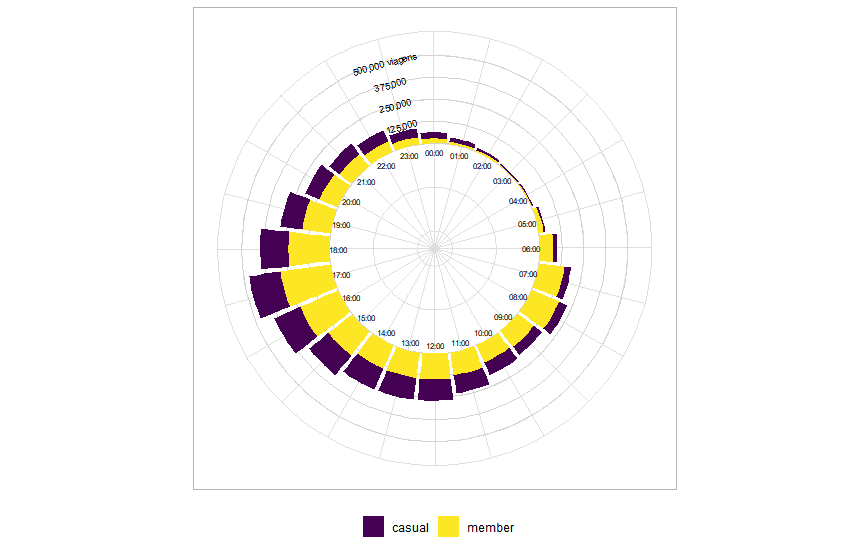
Este gráfico circular mostra que o horário mais popular do dia, tanto para membros anuais quanto casuais, é às 17:00. Mais além, os picos de uso dos membros anuais serem horários típicos de uma jornada de trabalho comum reforça a teoria de que os mesmos utilizam o serviço para irem ao trabalho.
Membros casuais, por sua vez, costumam utilizar o serviço mais durante os períodos da tarde e da noite, o que não só reforça a teoria de que estes usam o serviço mais para lazer, mas também como alternativa de transporte.
Por fim, mais um fator importante a ser analisado é a média de duração das viagens feitas pelos membros. Membros anuais possuem uma média de aproximadamente 13 minutos de duração por viagem, enquanto membros casuais possuem uma de aproximadamente 29 minutos. Estas médias, mais uma vez, reforçam as teorias anteriores.
4. Recomendações
Para transformar membros casuais em membros anuais, eu recomendo:
1. Fazer uma campanha de marketing focada em mostrar o serviço Cyclistic sendo usado no dia-a-dia
Como observado na análise anterior, ambos os tipos de membros utilizam a Cyclistic como alternativa de transporte. Uma campanha focada em ressaltar não só isso, mas também os benefícios de se ter uma filiação anual, pode ajudar a converter usuários casuais. Indo mais além, tal estratégia tem o potencial de mudar a opinião de que a Cyclistic é apenas um serviço turístico, mostrando como ela pode se encaixar perfeitamente na rotina dos moradores da cidade.
2. Concentrar e investir mais em anúncios e descontos durante finais de semana
As análises feitas levaram à conclusão de que, durante finais de semana, muitas pessoas usam o serviço casualmente. Tendo isso em vista, um foco maior em tal período tem mais potencial de transformar essas pessoas em membros, ainda mais se aliado à estratégia anterior.
Análise do mercado de Dados brasileiro
01/11/2022
1. Introdução
Este é um projeto pessoal, que comecei com o intuito de entender melhor as exigências para se entrar no mercado de dados no Brasil. O código fonte do projeto se encontra aqui.
Depois de observar as muitas dúvidas de quem deseja conseguir um emprego na área, além de tê-las eu mesmo, decidi fazer uma análise geral das vagas oferecidas pelas empresas no Linkedin.
Eu pretendo continuar atualizando e agregando informações neste projeto ao longo dos anos, para sempre estar atualizado sobre o mercado, e ajudar ainda mais quem quer que seja que acesse esta análise.
2. Processo
O primeiro passo foi coletar os dados necessários. Para isso, criei um web scraper que coletou os links de todas as 986 vagas do Linkedin oferecidas na área de data science no Brasil recentemente (01/11/2022). Destes links, extraí todas as informações relevantes: título, nome da empresa, local, método de trabalho (remoto, presencial ou híbrido), data da publicação, jornada de trabalho (tempo integral, meio período e contrato) e descrição. Devido a algumas vagas não possuírem todas essas informações, das 986, apenas 828 foram armazenadas em um dataframe com o nome de "job_offers". O código completo para esta fase pode ser encontrado aqui.
Com isso, o próximo passo foi limpar e tratar devidamente esses dados. Observando o dataset, percebi que muitas vagas de outras áreas da tecnologia foram erroneamente incluídas no filtro "data science" no Linkedin, portanto, usei uma série de palavras chaves para filtrar todas as vagas que realmente eram da área. O número total de entradas foi de 828 para 624.
Tendo enfim um dataset limpo, pude inicar a fase de tratamento. Comecei por simplificar os títulos de cada vaga, sintetizando-os nas categorias: Analista BI, Analista de Dados, Engenheiro de Dados e Cientista de Dados, e para isso utilizei regex em python, além de mais uma vez palavras chave. Após isso, usei esta mesma abordagem para extrair as informações mais relevantes das descrições de cada vaga, como o nível de educação formal e os conhecimento sobre tecnologias requeridos ou preferidos. Por fim, simplifiquei da mesma maneira que os títulos as jornadas de trabalho e os locais das empresas, retirei as colunas cujas informações já não eram mais necessárias e salvei o dataset limpo sob o nome de "clean_job_offers". O código completo para esta fase da análise pode ser encontrado aqui.
3. Análise
Após coletar, limpar e tratar os dados, utilizei o PowerBI para montar um dashboard com as informações obtidas.
3.1 Geral
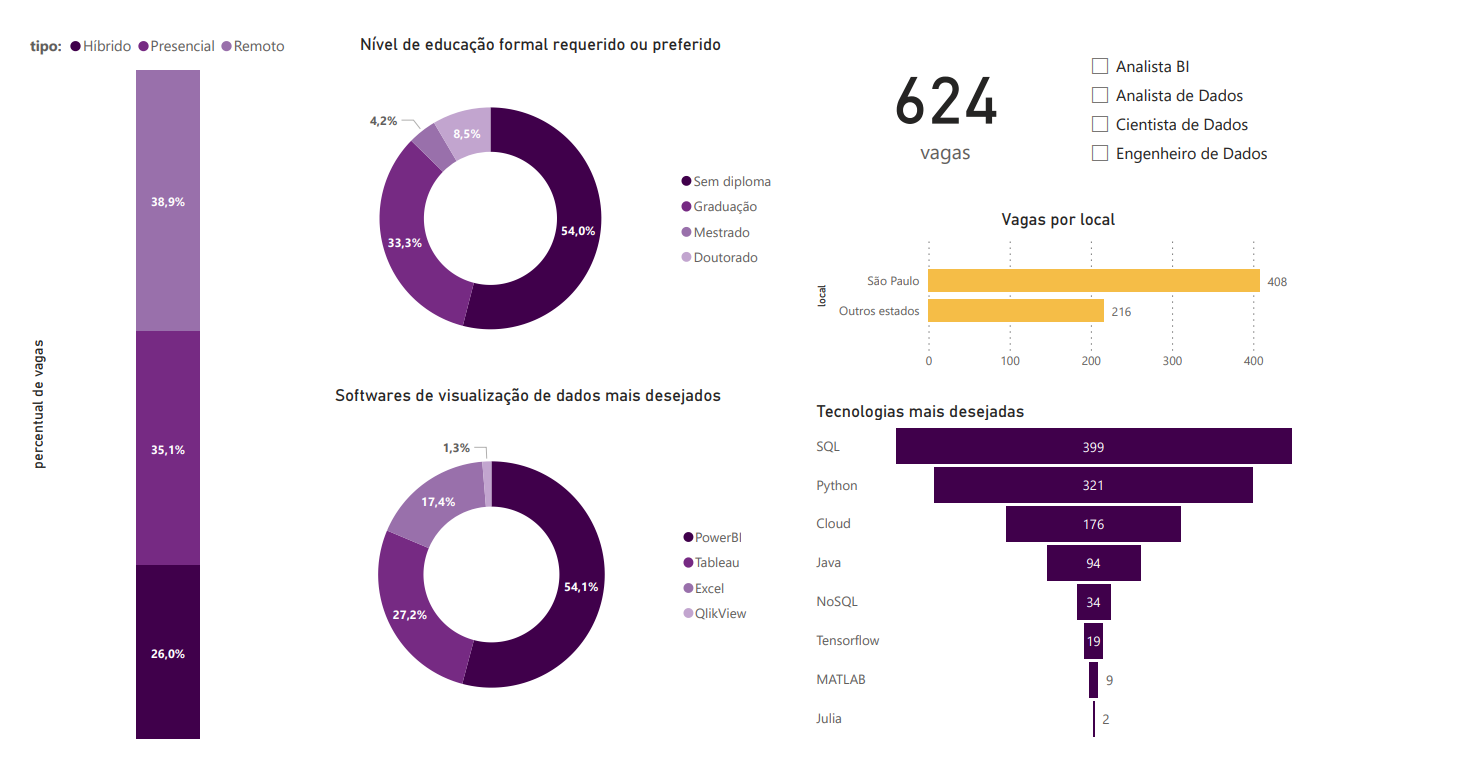
Observando os gráficos, notam-se alguns padrões que se repetirão pela maioria dos cargos. Em relação aos métodos de trabalho, remoto e presencial possuem uma distribuição bem balanceada, com o primeiro liderando por 4 pontos percentuais, enquanto o método híbrido, com apenas 26% do todo, demonstra uma adesão um pouco mais baixa que os anteriores.
Quanto aos níveis de educação formal requeridos ou preferidos, nota-se que mais da metade das vagas não exigem diploma. Uma possível causa de tal resultado pode ser o fato de que o mercado de dados ainda é muito novo, e poucas graduações na área existem nas universidades. Além disso, existe também a tendência geral do mercado tech de dar pouca importância a diplomas universitários e mais à habilidades técnicas, comprovadas por meio de projetos pessoais ou certificações oferecidas por cursos online.
Falando em habilidades, as três que mais se destacam como mais desejadas na área são Python, SQL e Power BI, todas presentes nos requisitos de mais da metade das vagas coletadas.
Por fim, pode-se observar a expressiva diferença entre o número de vagas em São Paulo e o número de vagas em outros estados do Brasil. Isso deve-se, provavelmente, ao fato de São Paulo ser o centro financeiro do Brasil, com a maioria das grandes empresas sediadas neste estado.
3.2 Analista BI
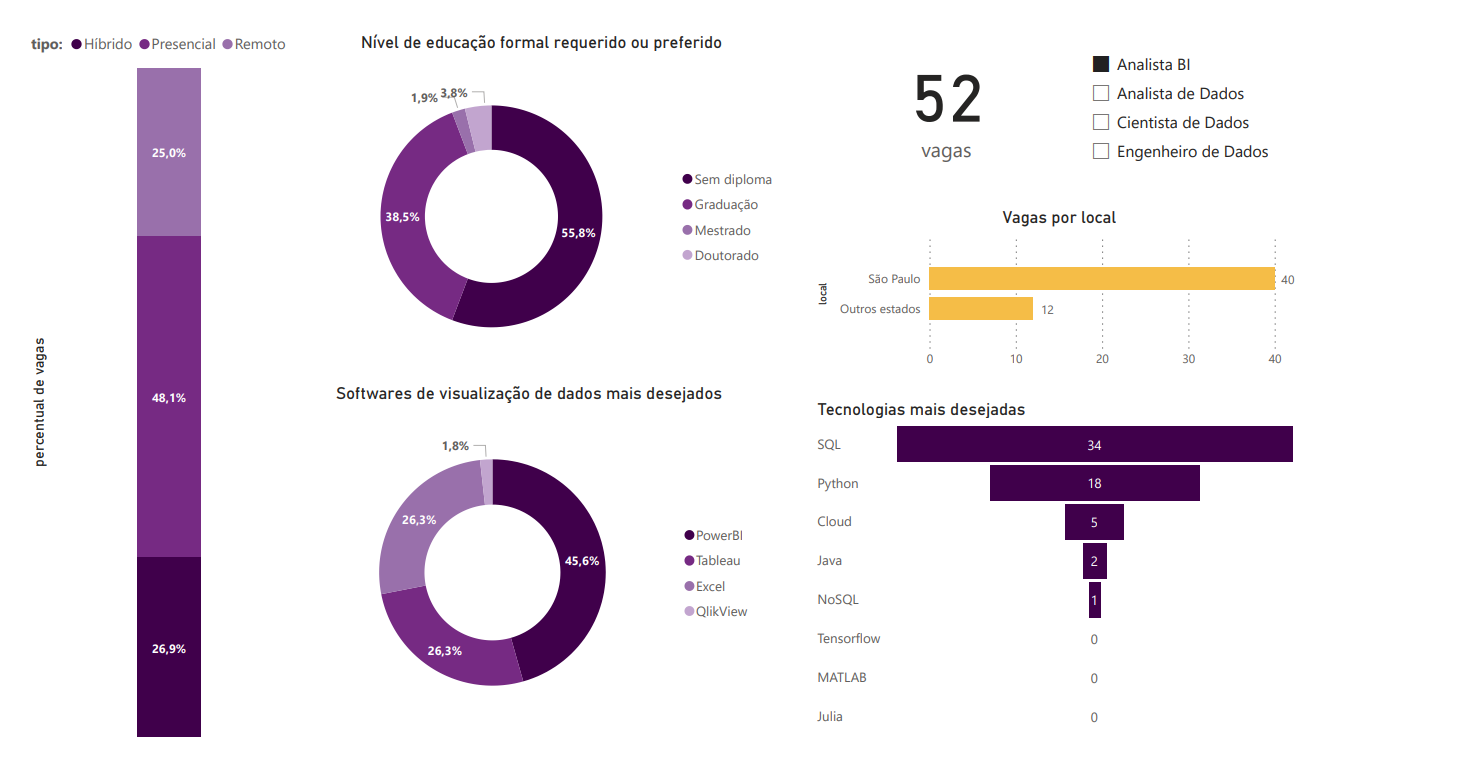
A primeira diferença aqui é o método presencial como o mais usado neste cargo. Uma possível causa disso pode ser a própria natureza do cargo, voltado mais a comunicação do que a parte técnica, mas um outro fator que também pode ter tido influência nesse resultado é o número baixo de vagas encontradas, algo a ser levado em conta em todos os outros resultados da análise deste cargo.
Outra grande diferença notada está no número de vagas por local, a maior entre todos os 4 cargos. A razão disso, provavelmente, está ligada mais uma vez ao fato de São Paulo ser o centro financeiro do Brasil, e devido à natureza mais focada aos negócios do cargo, esse fator se fortalece e engrandece a diferença.
Em relação às habilidades técnicas, observa-se uma importância maior do Excel nos requisitos, mas fora isso, os padrões permanecem aproximadamente os mesmos, assim como nos níveis de educação formal.
3.3 Analista de Dados
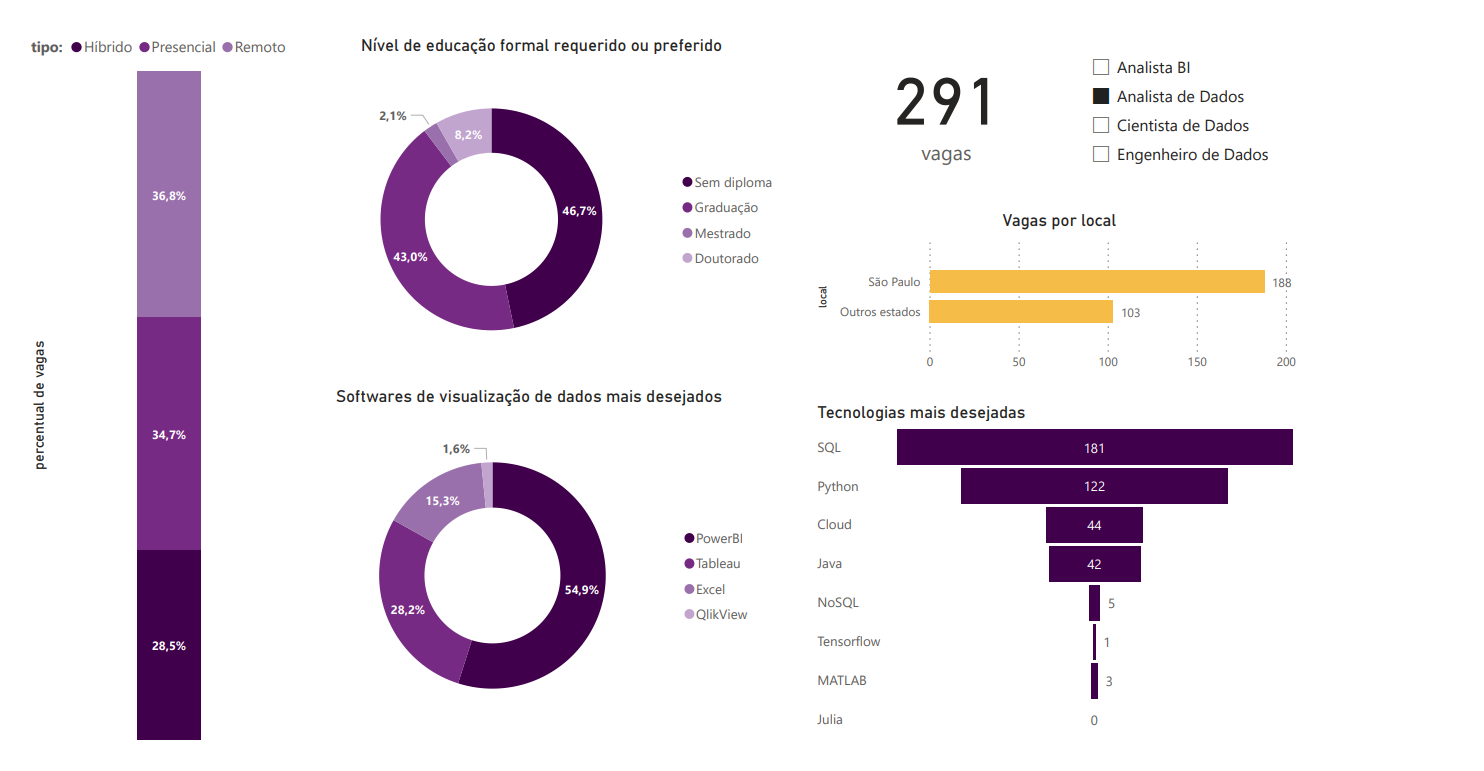
Os resultados mostrados pelos gráficos aqui não diferem muito dos mostrados pela análise geral, e isso se deve muito provavelmente por este ser o cargo com o maior número de vagas, quase metade do total.
Este número expresssivo, também, pode ser resultado da influência de um fator comentado anteriormente, o fato de que o mercado de dados ainda é muito novo, e muitas vezes as empresas acabam colocando o título de analista em um cargo que exige habilidades mais adequadas à um cientista ou engenheiro de dados.
Isso fica mais evidente ao perceber que este é o único cargo cuja maior parte das vagas exige ou prefere um diploma universitário, algo a se esperar mais de cargos mais complexos como os citados acima.
3.4 Engenheiro de Dados
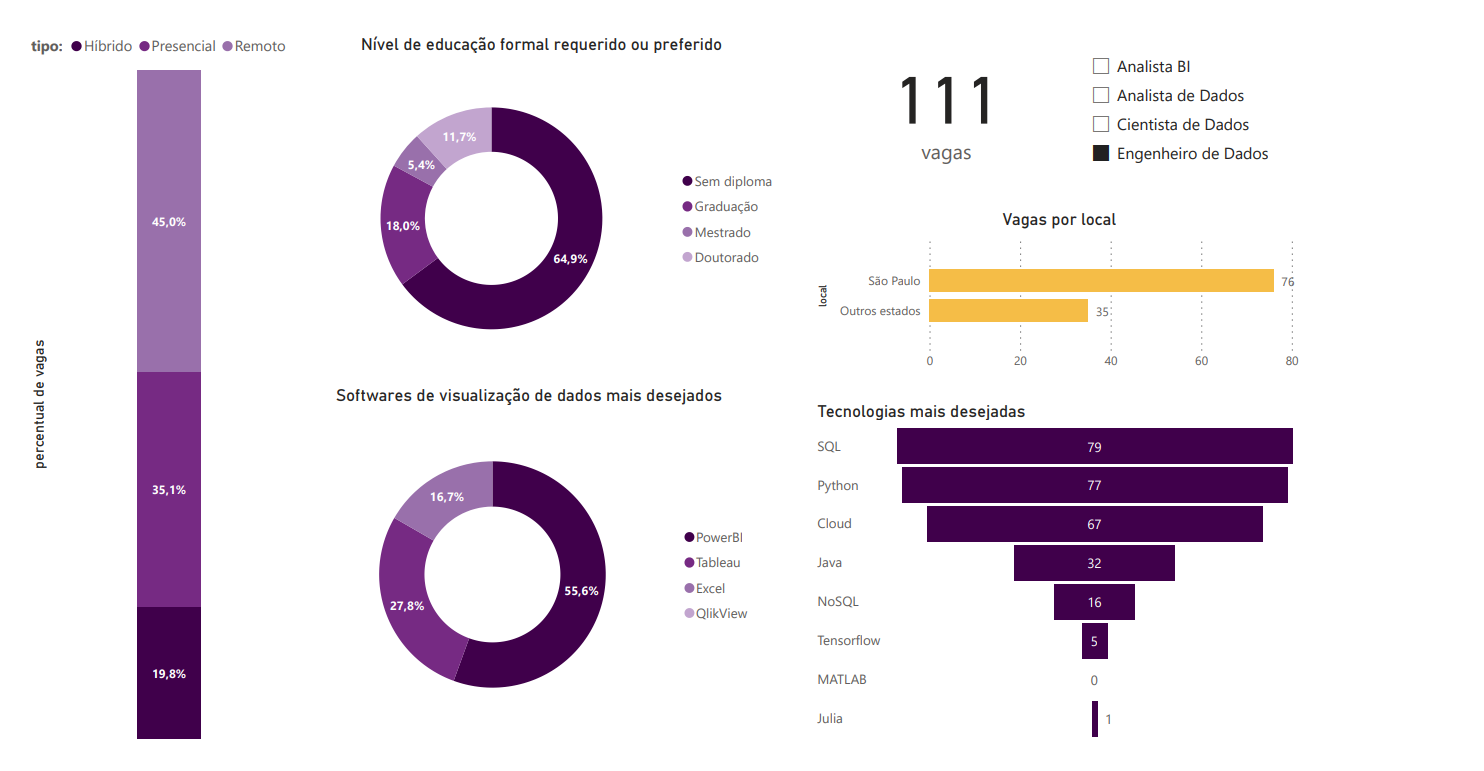
O mais interessante de se observar aqui é a maior importância dada ao conhecimento de tecnologias cloud, uma área fortemente ligada à engenharia de dados.
Além disso, percebe-se também uma alta no número de vagas remotas, e uma distribuição mais balanceada das tecnologias desejadas.
3.5 Cientista de Dados
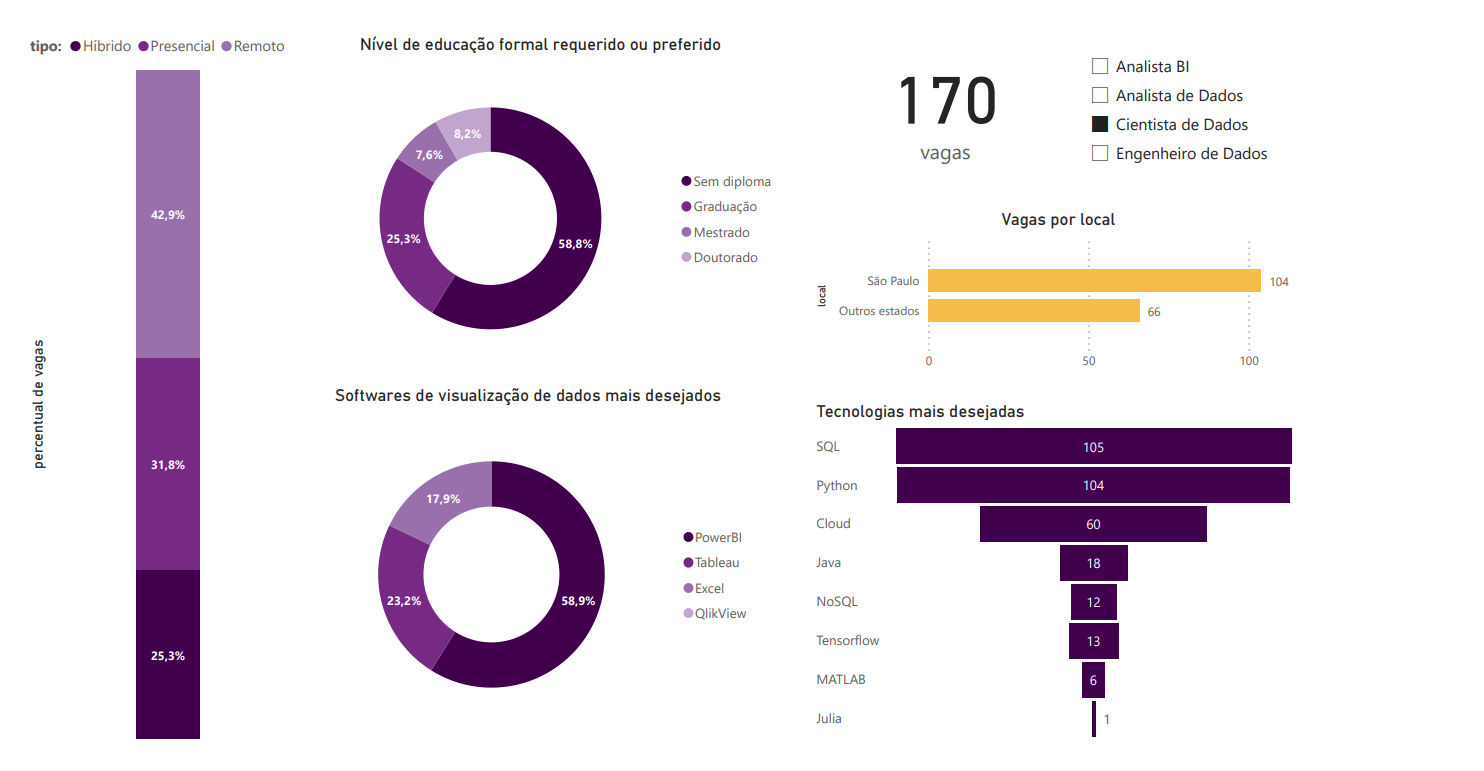
Os mesmos padrões observados na análise anterior podem ser vistos aqui, destacando a importância das tecnologias cloud nessas duas áreas, além da predominância do método remoto de trabalho.
Estudo de caso Bellabeat
08/03/2023
1. Introdução
Este é um estudo de caso realizado como projeto final do curso de especialização em Análise de Dados do Google. O código fonte do projeto se encontra aqui.
A Bellabeat é uma empresa de tecnologia do Vale do Silício, focada em produtos inteligentes de saúde, sendo estes:
Minha tarefa, neste estudo, foi analisar dados de aparelhos inteligentes fornecidos publicamente, para então aplicar meus insights na estratégia de marketing da empresa.
2. Processo
Primeiramente, coletei os dados em formato csv fornecidos na plataforma Kaggle. Todas as informações relevantes sobre tais dados se encontram aqui.
Em seguida, carreguei estes arquivos em planilhas Excel e criei uma tabela dinâmica para cada uma, para visualizar melhor as relações potencialmente relevantes. Comecei analisando o total de calorias queimadas por cada um dos 33 usuários durante o período de 1 mês da coleta, e então transformei esta tabela dinâmica em uma comum, para realizar uma operação lógica de IFs aninhados com a finalidade de dividir os usuários em 3 categorias: não muito ativos, ativos e muito ativos. Com isso, retornei à planilha principal de atividades e utilizei a função XLOOKUP para mapear cada ID de usuário com sua devida categoria.
Meu próximo passo foi criar outra nova coluna e preenchê-la com o nome do dia da semana de cada atividade registrada, usando uma combinação das funções TEXT e WEEKDAY, para poder analisar em quais dias os usuários costumam se exercitar mais.
Feito isso, decidi realizar uma análise semelhante por horários dessa vez, usando a função HOUR nas planilhas adequadas.
Por fim, limpei os dados filtrando registros e colunas irrelevantes para as análises que pretendia realizar e os transferi para o Power BI, onde conectei as tabelas através do ID, com uma relação ManyToMany. Além disso, também utilizei a linguagem DAX para criar outra coluna dos dias da semana, dessa vez em formato númerico, para ordenar corretamente nos gráficos feitos.
3. Análise
Usando o Power BI, montei um dashboard apresentando as informações com maior potencial de guiar as estratégias de marketing da empresa, com uma linguagem visual que realça os maiores valores em vermelho, e os demais em cinza gradual.
3.1 Geral
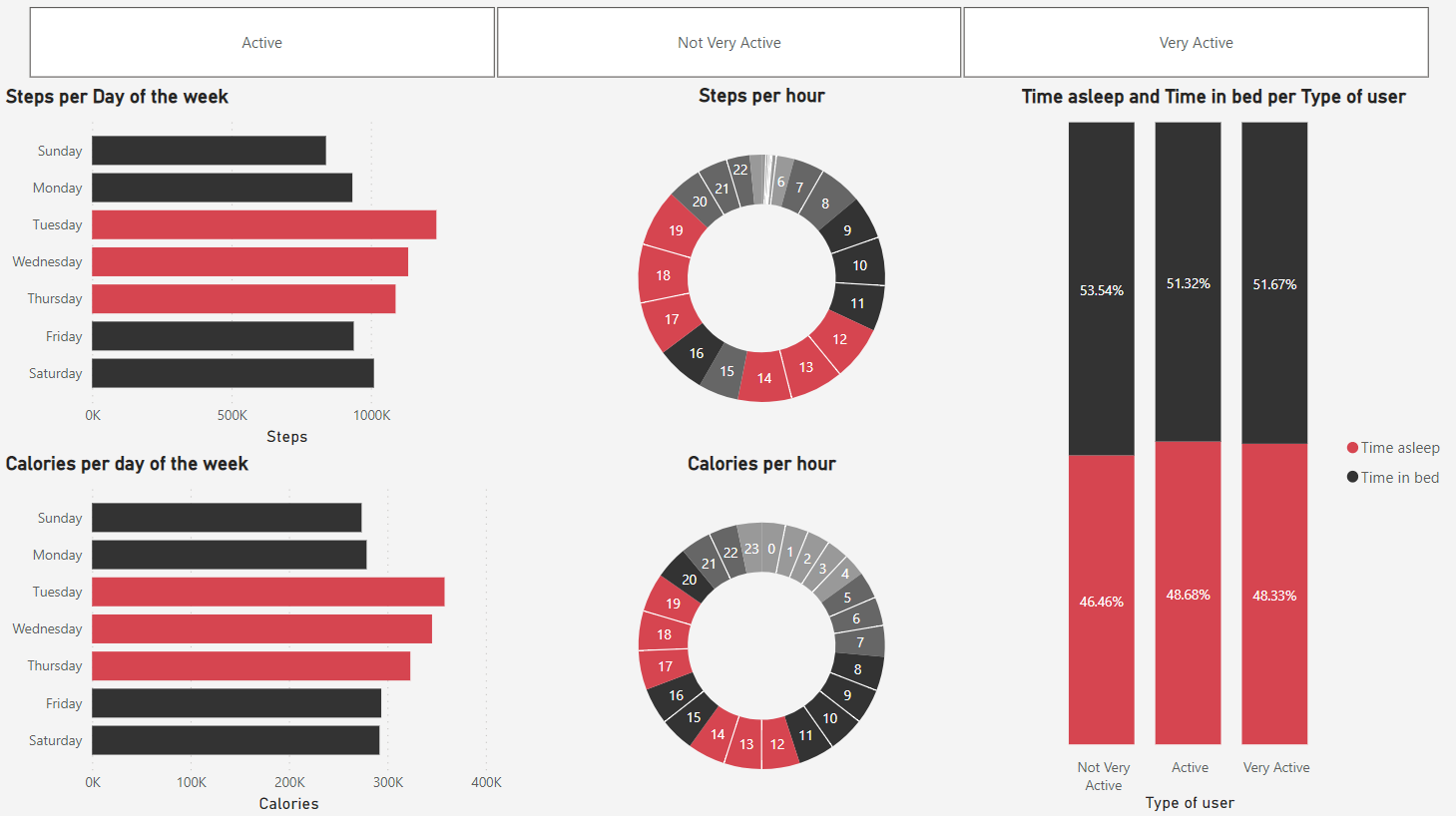
Aqui, podemos observar as tendências gerais, que mostram terça, quarta e quinta-feira, e o começo e o fim da tarde como os períodos onde mais há atividades físicas. Além disso, o último gráfico também apresenta uma qualidade de sono melhor nos usuários ativos e muito ativos, que possuem uma diferença positivamente menor entre o tempo total na cama e o tempo total dormindo.
3.2 Usuários não muito ativos
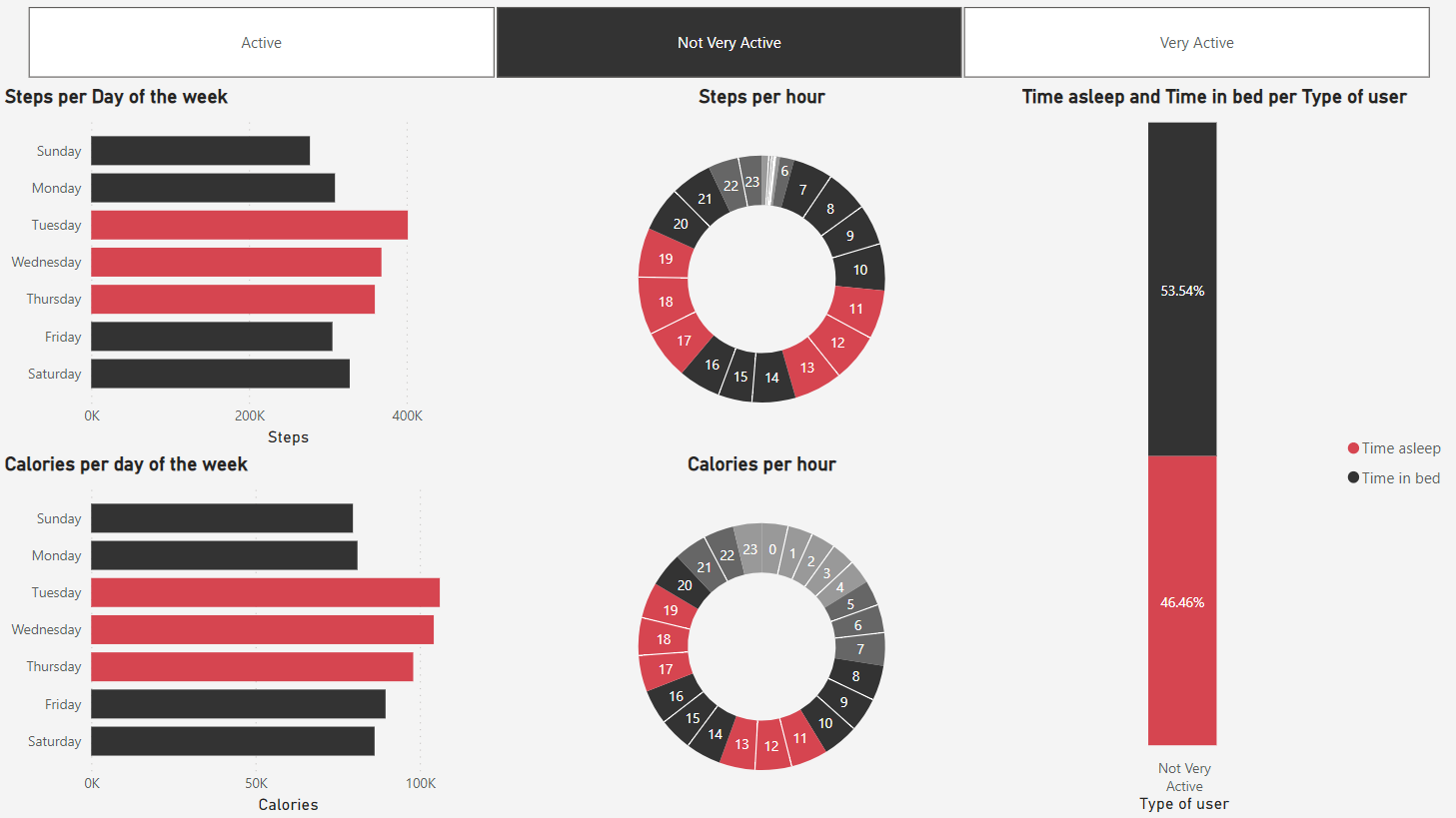
As tendências aqui não diferem muito das gerais, contudo, pode-se perceber uma preferência de se exercitar uma hora mais cedo por parte de tais usuários, durante a primeira parte do dia.
3.3 Usuários ativos
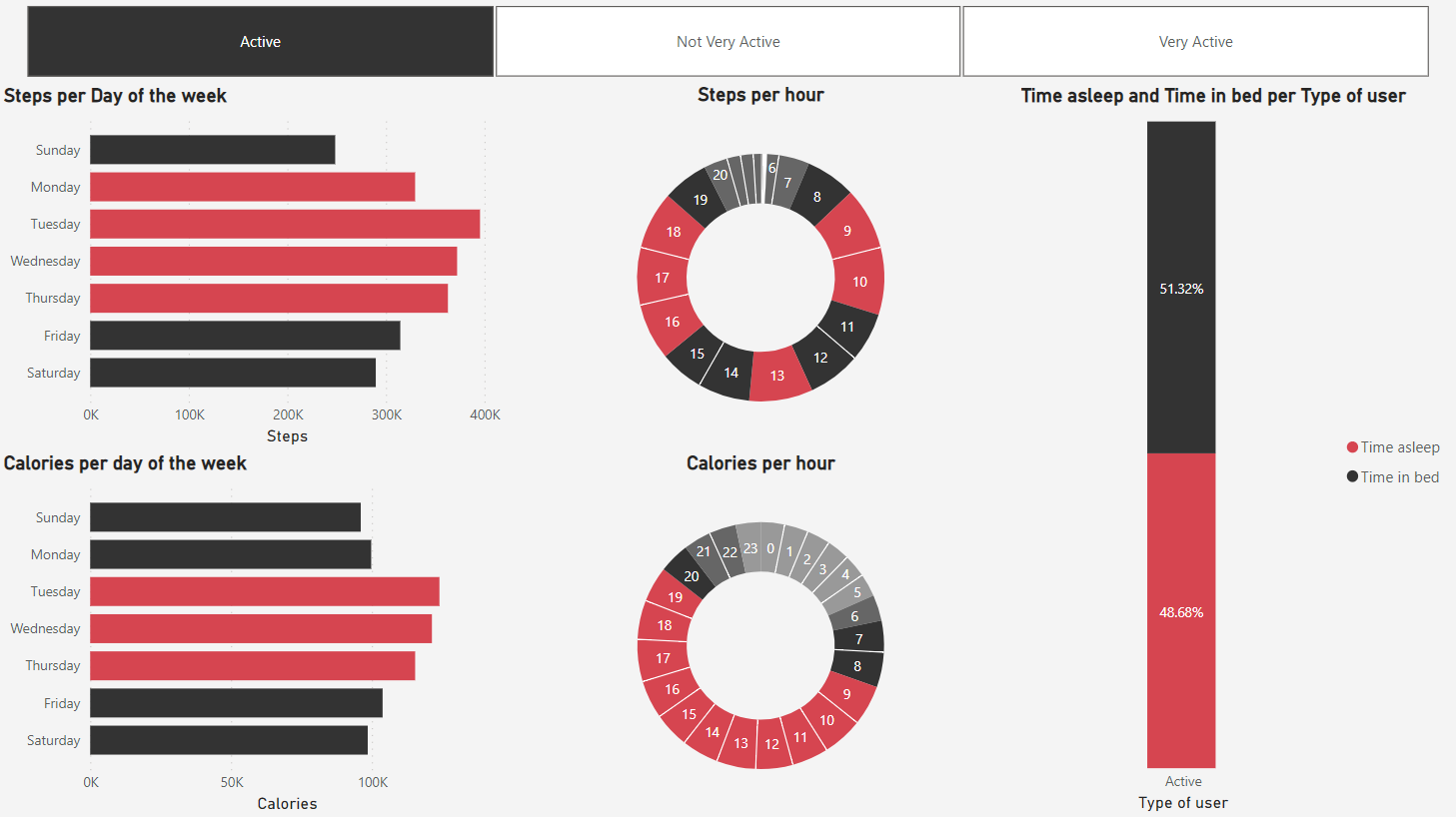
Estes usuários demonstram uma uniformidade maior de atividade física durante o dia, sem grandes intervalos de queima de calorias. Esta uniformidade se repete no gráfico de passos por dia da semana, o que demonstra uma estabilidade maior de rotina.
3.4 Usuários muito ativos
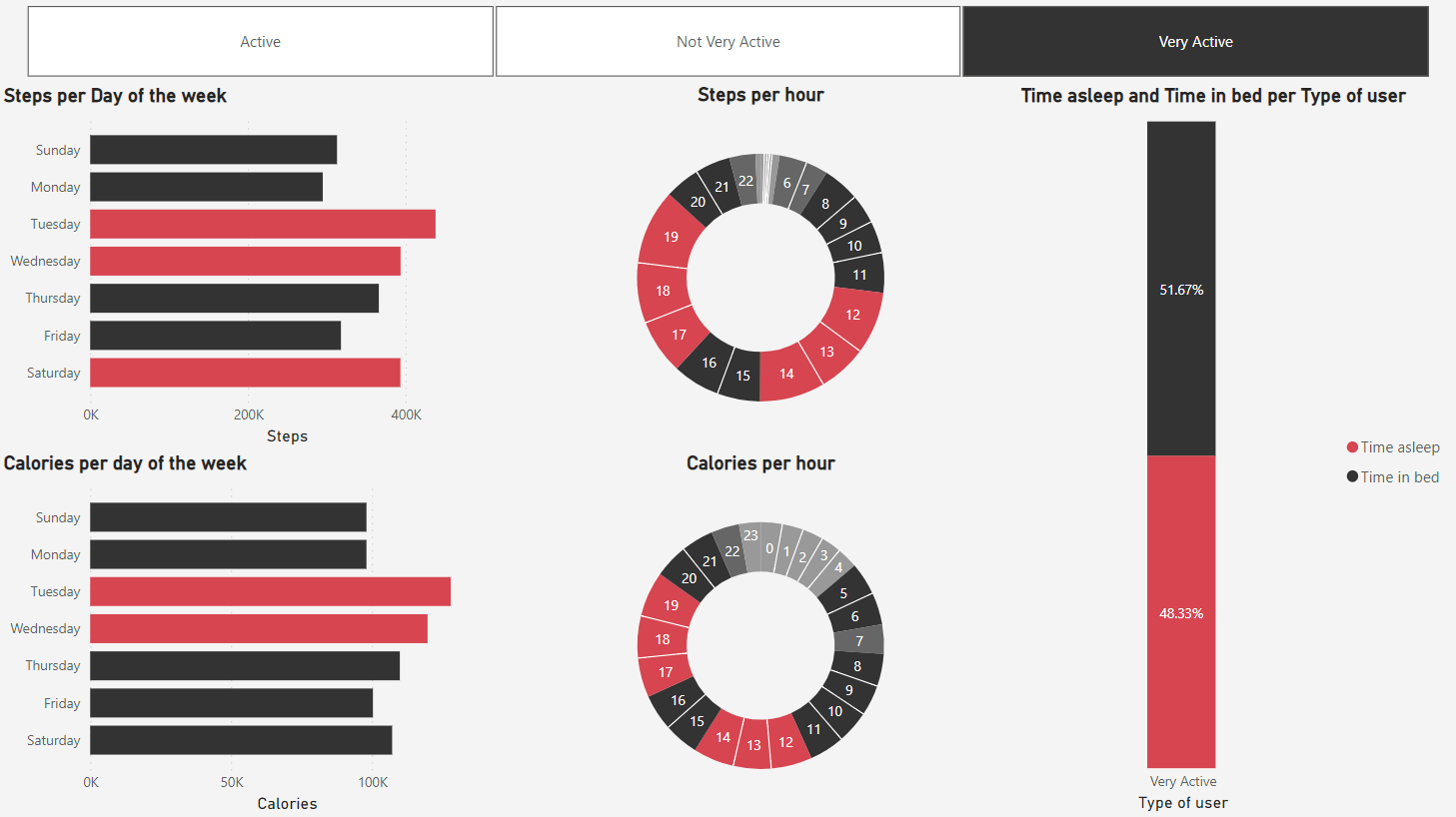
Os usuários desta categoria, por sua vez, apresentam um padrão mais formado por picos, que se dão majoritariamente nas terças, quartas e sábados, e nos horários do começo e fim da tarde também.
4. Recomendações
Para fortalecer os resultados das estratégias de marketing, minhas recomendações são:
1. Ressaltar a qualidade de sono
Como observado no dashboard geral, usuários mais ativos possuem uma qualidade de sono melhor. Recomendo apontar essa tendência nas futuras campanhas tanto para potenciais usuários quanto para usuários pouco ativos.
2. Notificar os usuários durante seus dias menos ativos
Ao mandar notificações de lembrete aos usuários durante os dias em que eles menos se exercitam, podemos alcançar um padrão mais uniforme de atividade, e consequentemente uma rotina e estilo de vida mais saudável.
3. Promover a garrafa Spring durante os horários onde há mais passos dados
Recomendo oferecer promoções e ofertas especiais durante o início e o fim da tarde, períodos onde os usuários mais caminham, e onde provavelmente estarão mais aptos a pensarem na própria hidratação.
Estudo de caso do Suporte ao Cliente do Google Fiber
06/07/2023
1. Introdução
Este é o projeto final do curso profissional de Business Intelligence do Google, oferecido através do Coursera.
Google Fiber é um produto da Alphabet que fornece a pessoas e negócios internet fibra ótica. O objetivo desta análise é explorar tendências de ligações repetidas no setor de suporte ao cliente deste produto, para entender melhor o quão efetivo é o time em resolver os problemas e dúvidas dos clientes na primeira ligação, além de mapear um caminho para melhorar a experiência do mesmo como um todo.
2. Processo
Os dados para a análise foram disponibilizados separadamente, na forma de três arquivos CSV, cada um com 450 linhas e 11 colunas. Tais dados já haviam sido anonimizados, e as informações inclusas são:
- date_created: A data da criação de cada registro.
- contacts_n: O número de primeiras ligações.
- contacts_n_1 - contacts_n_7: O número de ligações feitas após n dias da primeira.
- new_type: O tipo de problema abordado nas ligações, sendo estes:
- Tipo 1: gerenciamento de contas.
- Tipo 2: solução de problemas técnicos
- Tipo 3: agendamento
- Tipo 4: construção
- Tipo 5: internet e wifi
- new_market: Uma de três cidades, que representa o mercado de onde as ligações vieram. Cada arquivo CSV se refere a somente 1 das 3.
Após baixar os arquivos CSV referentes aos 3 mercados diferentes, eu os juntei em uma só tabela usando um script SQL através da plataforma BigQuery. Assim, levei esta tabela ao Tableau e criei campos calculados para representar quantos por cento dos clientes que realizaram suas primeiras ligações precisaram ligar novamente, entre 1 a 7 dias depois, para resolverem seus problemas.
Usando os números totais de ligações e tais campos calculados, montei um dashboard, dividido por setores com gráficos mostrando diferentes relações, para visualizar e analisar as tendências de ligações repetidas através dos mercados, dos tipos de problemas e das diferentes datas.
3. Análise
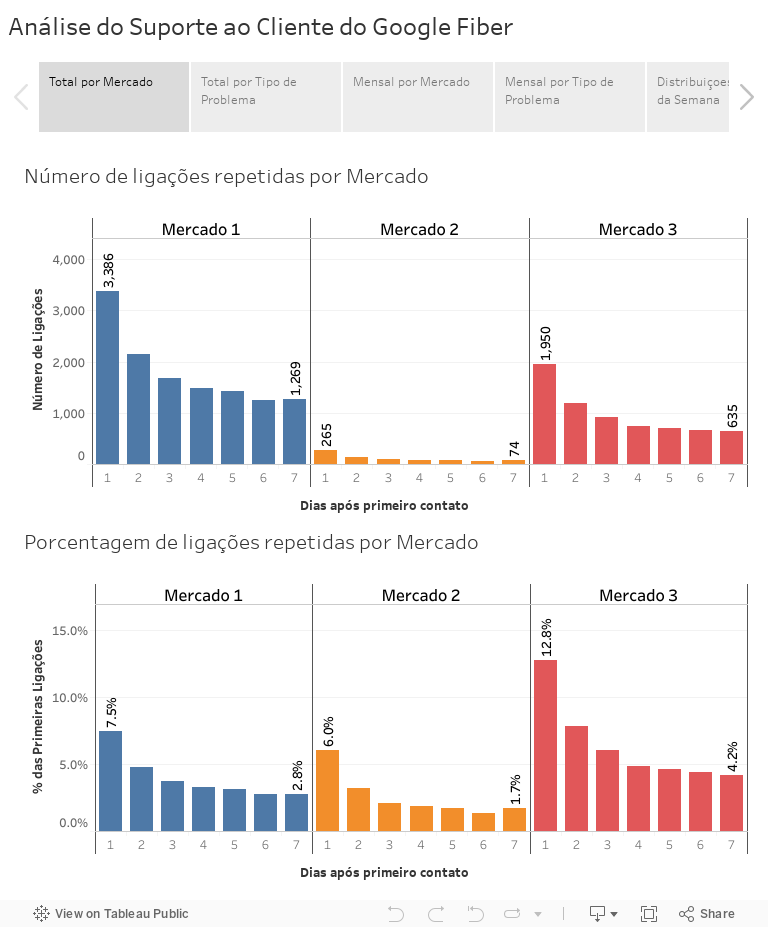
Nos primeiros dois setores do dashboard, nota-se que o mercado 1 e o tipo 5 são as maiores fontes de ligações repetidas em questão de números. Porém, analisando sob a ótica percentual, o mercado 3 e o tipo 1 são os que mais geram ligações repetidas após o contato inicial, mostrando que estas são as áreas com maior dificuldade de resolver os problemas e dúvidas dos clientes.
Nas análises mensais, pouca variação é observada ao longo dos meses em cada mercado, a maior delas sendo, novamente, do mercado 3, que atinge seu ápice no mês de fevereiro. Em relação aos tipos de problemas, tanto o tipo 1 quanto o tipo 4 apresentam variações significativas, o primeiro atingindo seu ápice também em fevereiro, sendo também a maior porcentagem de todas do gráfico, e o segundo em janeiro, com um padrão de variação bem diferente dos demais.
Por fim, as distribuições por dias da semana mostram que segunda-feira é o dia que mais recebe ligações durante os meses de janeiro e fevereiro, nos mercados 1 e 2, e sobre os tipos 1 e 2. No mês de março e no tipo 5, o dia que mais concentra ligações se torna quarta-feira, enquanto que no mercado 3 e no tipo 3, é na sexta-feira que mais se recebem ligações.
4. Recomendações
Minha recomendação geral seria uma análise mais detalhada de dados específicos do Mercado 3 e das ligações relacionadas ao tipo de problema 1, para obter uma compreensão melhor do por quê tais áreas possuem mais dificuldade de resolver os problemas dos clientes com uma única ligação.
Além disso, recomendo, a longo prazo, focar as análises pela ótica percentual, pois esta oferece uma visão mais alinhada com o objetivo do Suporte ao Cliente de otimizar a eficácia do time em resolver os problemas e dúvidas dos usuários.
Análise das vendas de uma empresa de varejo de bicicletas
11/08/2023
1. Introdução
Neste projeto, eu tinha como objetivo construir um dashboard para os executivos da empresa, detalhando os padrões e tendências das métricas de vendas nos períodos liberados da base de dados, de forma clara e organizada.
Para realizar isso, utilizei Microsoft SQL Server para criar e manipular os dados, Excel para tratá-los e Tableau para a construção do dashboard final.
2. Processo
O primeiro passo foi criar a base de dados para conseguir extrair dela as informações necessárias. Isso foi feito usando arquivos SQL, baixados no site sqlservertutorial.net, para criar os esquemas e tabelas, assim como para inserir os dados em tais objetos.
Feito isso, pude criar uma query (que pode ser vista aqui) para extrair as informações relevantes e juntá-las em uma só tabela, com as colunas:
- order_id: a identificação da venda.
- customer: o nome do cliente que realizou a compra.
- city: a cidade onde a venda foi efetuada.
- state: o estado onde a venda foi efetuada.
- order_date: a data da venda.
- total_units: a quantidade de produtos vendidos.
- revenue: o lucro total.
- product_name: o nome do produto.
- category_name: a categoria do produto.
- store_name: o nome da loja responsável pela venda do produto.
- sales_rep: o nome do representante responsável pela venda.
3. Análise
Depois de conectar o banco de dados SQL ao Excel, usei tabelas e gráficos dinâmicos para analisar as relações entre os dados e criar um dashboard inicial.
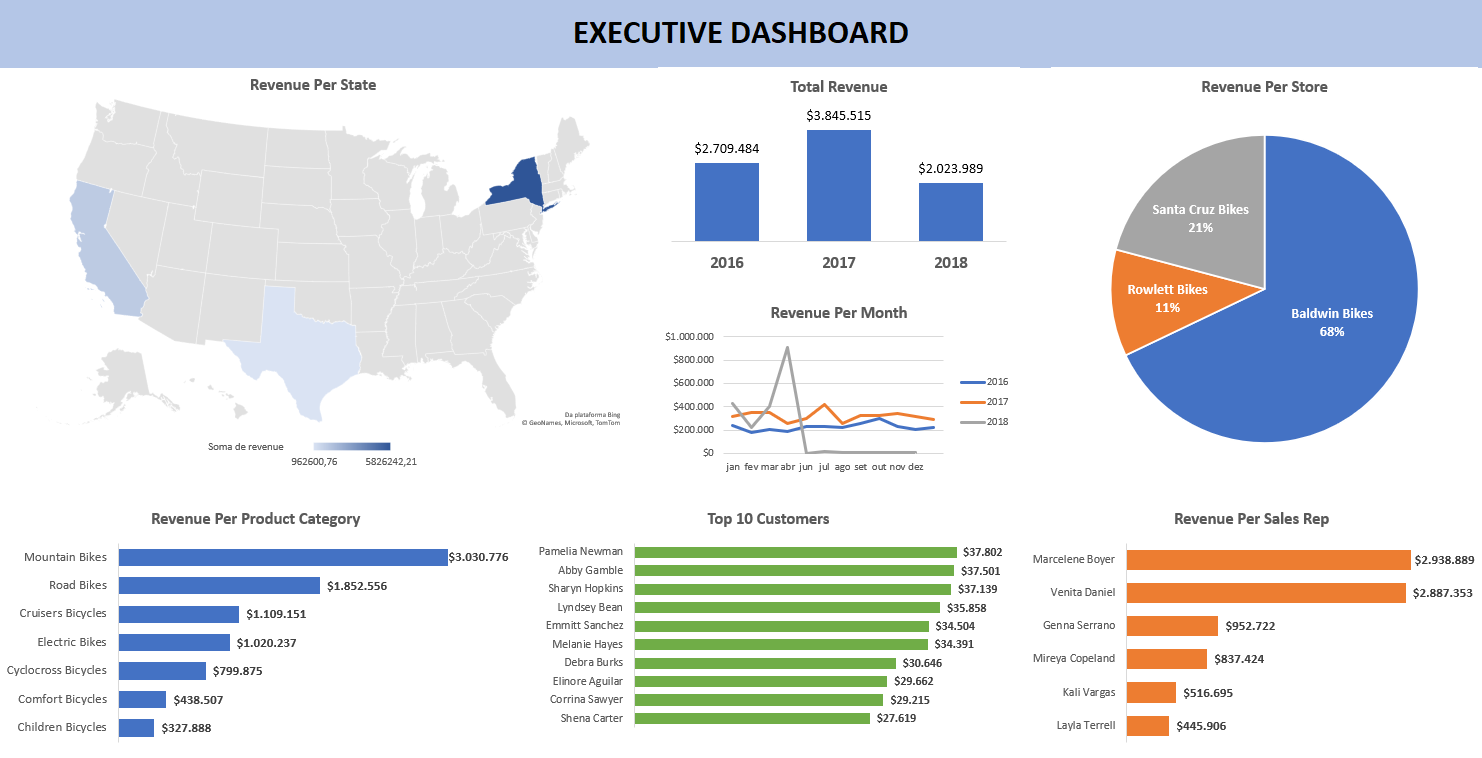
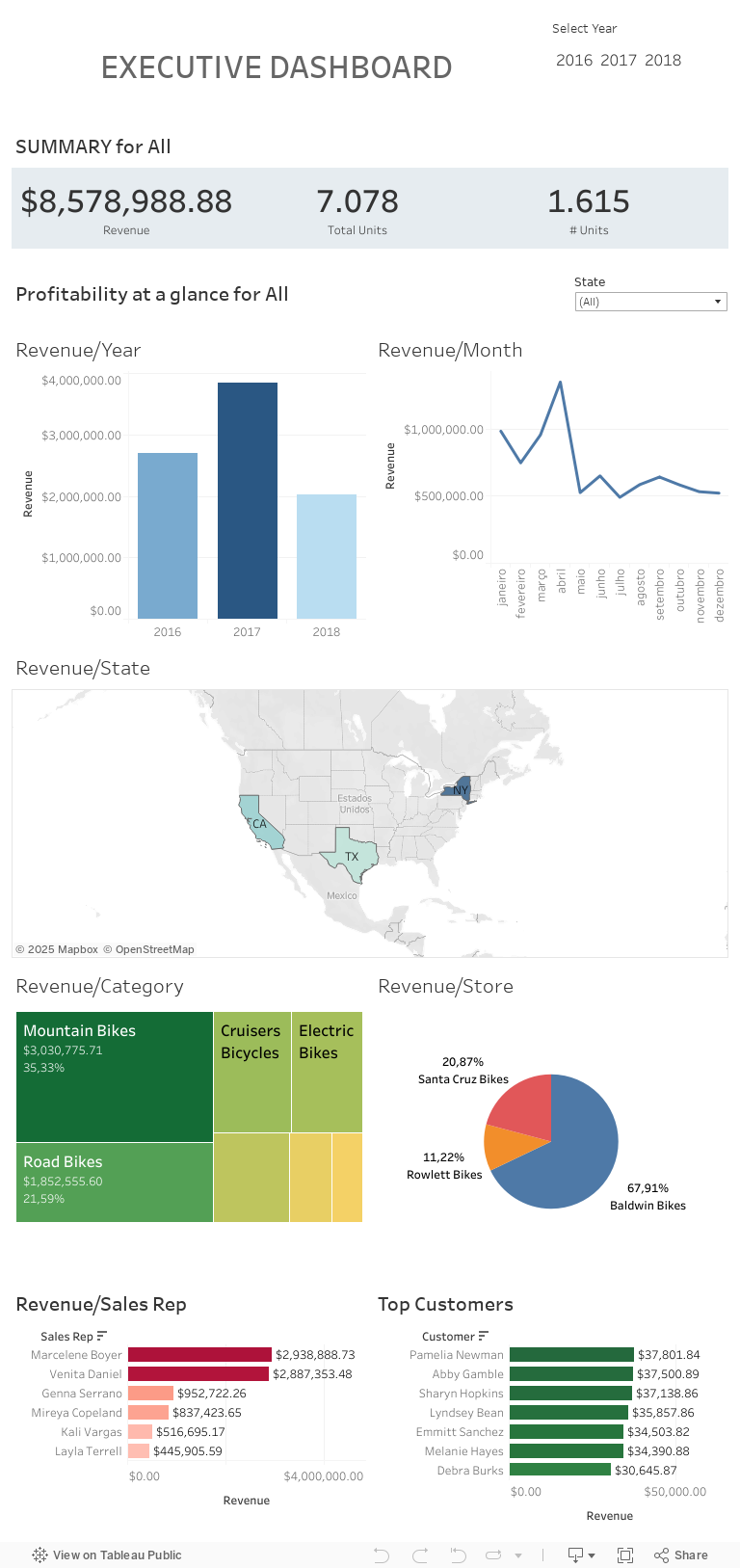
A partir deste esboço, construí o dasboard final no Tableau, mais detalhado e interativo, com todas as informações necessárias para auxiliar as tomadas de decisão do time executivo.
Análise de uma rede de hotéis
17/08/2023
1. Introdução
O objetivo desta análise era de responder, com um dashboard, 3 dúvidas da gerência desta rede: se o lucro dos hotéis estava crescendo ao longo dos anos, se o tamanho dos estacionamentos deveria ser aumentado e quais outras tendências poderiam ser exploradas.
Para isso, utilizei queries SQL através do BigQuery para extrair os dados necessários, Power Query para manipulá-los e Power BI para contruir o dashboard.
2. Processo
Primeiro, baixei os dados no formato .xlsx, encontrados no site absentdata.com, separei-os em planilhas individuais e os converti para o formato CSV.
Feito isso, pude criar a base de dados e as tabelas no BigQuery, assim como as queries necessárias para a análise, que podem ser visualizadas aqui.
Partindo para o Power BI, criei uma conexão com o BigQuery e, usando Power Query, escrevi uma fórmula para calcular o lucro total de cada registro usando o número de noites, a diária, o desconto e o preço das refeições. A tabela final ficou com as seguintes colunas:
- hotel: O tipo de hotel
- stays_in_weekend_nights: Número de noites durante o fim de semana
- stays_in_week_nights: Número de noites durante a semana
- country: País do hotel
- adr: Diária cobrada
- required_car_parking_spaces: Número de vagas utilizadas no estacionamento
- reservation_status_date: Data da reserva
- Discount: Desconto aplicado
- meal_cost: Preço cobrado pelas refeições
- revenue: Lucro total
Para finalizar, utilizei a linguagem DAX para criar um campo calculado do total de noites reservadas nos hotéis, e usando este, criei outro para a porcentagem de vagas ocupadas.
3. Análise

Analisando o dashboard, pode-se observar que o lucro dos hotéis, como já era de se esperar, possui seus picos em épocas comuns de férias, e se mostrava em crescimento até o início da pandemia do COVID-19.
Em relação ao tamanho dos estacionamentos, não há indício de que seja necessário aumentá-lo ainda, pois apenas uma pequena porcentagem deles é usado.
Por fim, seria interessante uma análise mais especializada da correlação entre as métricas do preço da diária e desconto com o crescimento geral do lucro, e talvez tornar o foco maior da rede em lazer e outras amenidades mais voltadas aos períodos de férias e feriados, onde se encontram os picos de lucro.